I've been exploring the handy async over the last few days in the lab. One of my projects is a MongoDB API Adapter in Node.js and I was pleased by a novel way of handling control flow.
async.auto() is a function offered by the libary which allows you to declare a set of tasks and their dependencies, then the library determines the best way to compose the initialization.
Consider the following dependency graph:
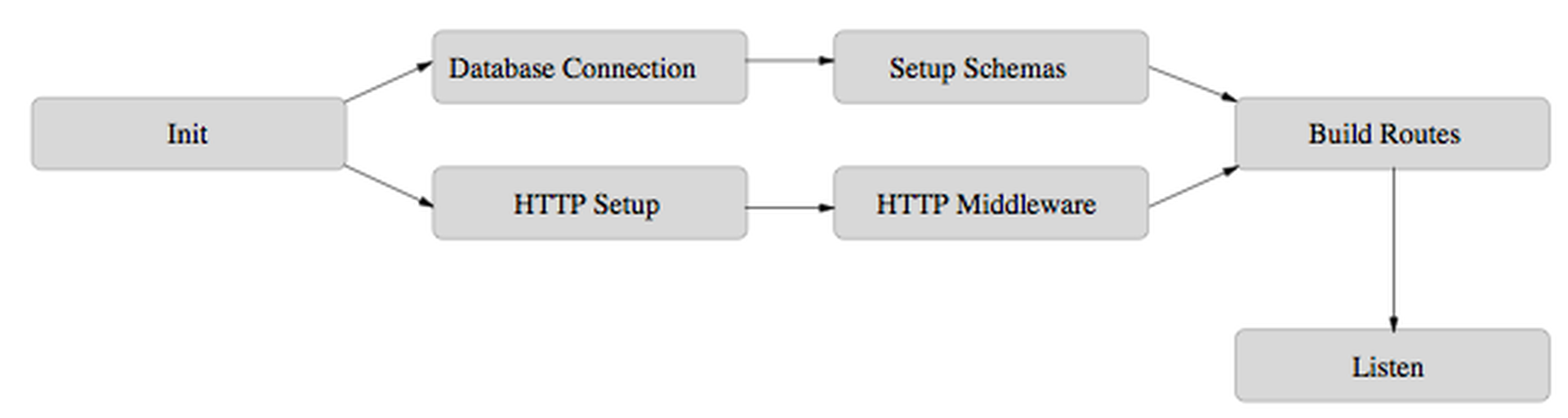
With async this could be modelled like so:
(function init() {
async.auto({
dbConn: dbConn,
schemas: [ 'dbConn', schemas ],
http: http,
httpMiddleware: [ 'http', httpMiddleware ],
routes: [ 'http', 'schemas', routes ]
}, listen);
// Definitions of functions below.
}());The first parameter of the function is an object of tasks. They follow the format taskName: function or taskName: [dependencies, function]. Tasks with dependencies will only start when those have been resolved.
So async helps with the handling of dependencies, but can we handle dependant state?
For example, dbConn produces a connection variable, and schemas consumes it. The two functions look like this:
function dbConn(callback) {
var connection = db.connect(someString).connection
connection.on('success', function () {
// Return `connection` into the `results`
callback(null, connection);
});
connection.on('error', function (error) {
callback(error, null);
});
}
function schemas(callback, results) {
// Do a bunch of stuff.
// results.dbConn has the connection.
callback(null);
}The result values of any task which another depends on are populated into the results parameter.
Finally, the listen function accepts a final (error, results). Note it's called as soon as any task returns an error, so always make sure to handle errors. Finally, results will have all of the return values of the tasks which were composed.
This provides a compelling way to handle composability and dependencies without having to deal with complex callback changes. Functions will be invoked as their dependencies are resolved, and it's easy to add or remove dependencies, changing what's available in results.
Give this pattern a try, it's especially useful when combined with other functions available in async, like async.seq.